BOJ 추천 프로젝트 (1)
LLM으로 interaction이 가능한 알고리즘 문제 추천 서비스 개발.
구조도
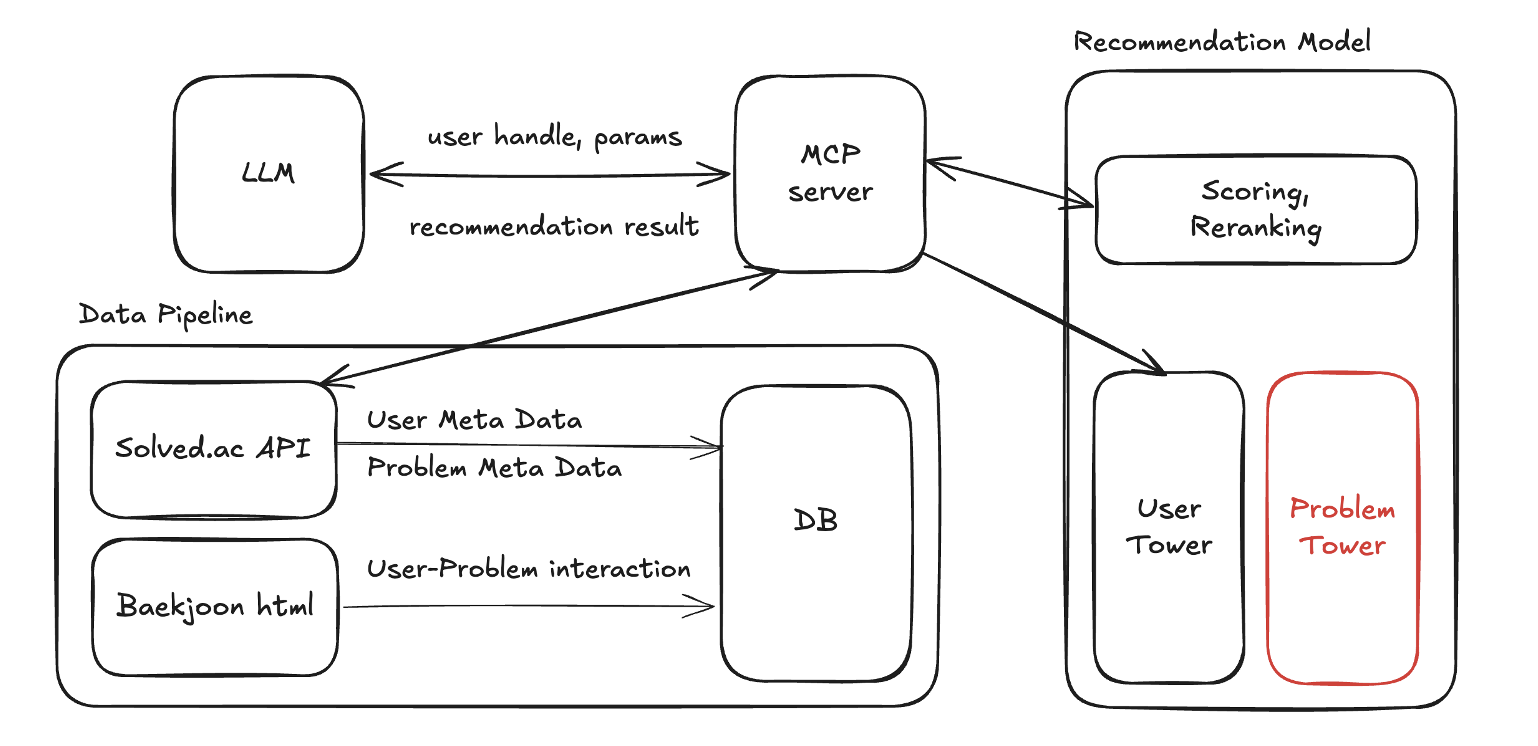
유저의 문제 풀이 sequence를 활용하여 개인화된 문제 추천 시스템 개발
실제 서빙 환경을 고려하여, 성능과 latency를 모두 높이는 것이 목표이다.
Data
Entity 설계
일단 sqlite로 간단하게 크롤링된 데이터를 저장하기 위한 DB를 생성했다.
유저, 문제, 인터랙션 테이블을 생성하고 유저, 문제 테이블은 autoincrement PK를 부여했다. 처음에는 user handle과 문제 번호가 고유 값이기 때문에 이 값을 통해 PK를 구현하려고 했지만, 모델을 학습하는 과정에서 index로 변환하고, 최종 inference에서 다시 실제 값으로 변경하는 과정이 필요했다. 이 과정을 단순화하고, 모든 모델에 동일한 index mapping을 적용하기 위해, autoincrement PK를 생성했다. 자주 접근 되는 handle과 problem_id에는 index를 추가했다.
class Users(Base):
__tablename__ = "users"
id = Column(Integer, primary_key=True, autoincrement=True)
handle = Column(String(255), unique=True, nullable=False)
solved_count = Column(Integer)
user_class = Column(Integer)
tier = Column(Integer)
rating = Column(Integer)
rival_count = Column(Integer)
reverse_rival_count = Column(Integer)
max_streak = Column(Integer)
rank = Column(Integer)
class Problems(Base):
__tablename__ = "problems"
id = Column(Integer, primary_key=True, autoincrement=True)
problem_id = Column(Integer, unique=True, nullable=False)
title = Column(String)
is_solvable = Column(Integer)
accepted_user_count = Column(Integer)
level = Column(Integer)
average_tries = Column(Integer)
tags = Column(String(1023)) # tags를 String으로 변경
class Interactions(Base):
__tablename__ = "interactions"
id = Column(Integer, primary_key=True)
user_id = Column(Integer)
problem_id = Column(Integer)
timestamp = Column(DateTime)데이터 수집
solved.ac에서 제공하는 API를 활용하여 사용자 정보와, 문제 정보를 추출한다.
유저, 문제 interaction에 대한 정보는 solved.ac API를 활용하는 것보다, 백준 문제 사이트에서 직접 크롤링하는 것이 더 효율적이다.
2025.04.19 기준, 백준 사이트에 제출 된 횟수는 약 9300만 건으로 모든 interaction 데이터를 수집하고 활용하기에는 너무 많았다. 크롤링을 하기 위해선 너무 많은 시간이 필요하고, 용량 문제로 전체 데이터를 모델 학습에 활용할 수도 없었다.
먼저 학습에 활용할 유저를 샘플링했다. 실버 1 이상의 유저 중 절반을 샘플링하여 약 30000명의 유저 meta 정보를 저장했다. 티어가 낮은 유저는 문제 풀이 이력이 적어, sequence 정보를 활용하기 어렵다.
유저-문제 interaction 데이터 수집
-
유저 프로필:
https://www.acmicpc.net/user/{handle}페이지를 BeautifulSoup 라이브러리를 활용하여 전체 문제 풀이 이력을 한 번에 크롤링히기. 하지만, 이 방법은 문제 풀이 순서 정보는 얻지 못한다. -
문제 셋 필터링:
https://www.acmicpc.net/problemset?sort=rac_desc&user={handle}&user_solved=1&page={page_num}형식으로 정렬을 하면, 문제 풀이 이력 순으로 크롤링을 할 수 있다. 하지만 이 방법도 정확한 timestamp는 얻지 못한다. -
제출 이력 필터링:
https://www.acmicpc.net/status?user_id={handle}&result_id=4&top={제출번호}페이지에서 문제 번호와 timestamp를 크롤링한다. 정확한 timestamp까지 얻을 수 있다.
최종적으로 3번의 방법을 통해 interaction 정보를 크롤링 했다. sequential은 일반적으로 아이템의 순차적인 정보만 있으면 되지만, 실제 서빙 환경에서 log를 활용하는 상황을 가정하기 위해, timestamp까지 추출했다.
crawling tip
800만건의 interaction을 수집하기 위해서는, 페이지당 20건의 interaction이 있는 url에 40만 번의 요청을 보내야 했다. 병렬 처리를 하지 않으면 수 일이 걸리는 작업이었기에, 병렬 처리가 필수적이었다.
User Agent List를 활용하여 매 요청에 user_agent를 random으로 요청하면, 202 Accepted를 보내는 것을 피할 수 있다. 너무 많은 요청에 대해 요청을 수락은 하지만, 처리는 하지 않는 방법을 쓰는 것 같다. 이 방법을 통해 몇 시간 안에 800만 건의 interaction 정보를 크롤링 할 수 있었다.
# 병렬 처리
with ThreadPoolExecutor(max_workers=max_workers) as executor:
future_to_user = {executor.submit(process_single_user, user, problem_mapper, db): user for user in users}# Random User Agents
def get_user_agents():
"""
Reads user agents from a file and returns them as a list.
"""
user_agents = []
file_path = os.path.join(os.path.dirname(__file__), 'agents.txt')
with open(file_path, 'r') as file:
for line in file:
user_agents.append(line.strip())
return user_agents
def get_random_user_agent():
"""
Returns a random user agent from the list of user agents.
"""
user_agents = get_user_agents()
return random.choice(user_agents)
if __name__ == "__main__":
# Example usage
print(get_random_user_agent())
headers = {
"Accept": "application/json",
"User-Agent": get_random_user_agent(),
}
res = requests.get(base_url, params=params, headers=headers)
마치며
서빙을 고려해서 모델을 설계하는 것은 처음이라 설계 단계에서 부터 어려움이 있었다. DB에 없는(학습에 활용하지 않은) 유저에 대한 추천을 제공하기 위해, Two Tower 구조의 online serving을 계획했다.
데이터를 직접 크롤링하여 학습, 평가 데이터셋을 만들어 보는 것이 처음이라 효율적으로 크롤링하는 함수를 작성하는 것 부터 쉽지 않았다..