Solar Teacher
"백지 공부법의 효율을 극대화하는 LLM 기반 학습 피드백 & 퀴즈 생성 서비스"
- 기간: 2025.01 ~ 2025.02 (Boostcamp AI Tech 4조, 팀 프로젝트)
- 역할: AI/Backend Developer (RAG 구축, 평가 데이터셋 생성, 프롬프트 엔지니어링)
- 한 줄 소개: 사용자가 작성한 필기 노트(백지 공부)를 OCR로 인식하고, RAG를 통해 개념 오류를 피드백하며 맞춤형 퀴즈를 제공하는 에듀테크 서비스

GitHub: boostcampaitech7/level4-recsys-finalproject-hackathon-recsys-04-lv3
Upstage course: Solar Teacher 코스
프로젝트 개요
'백지 공부법'은 효과적이지만, 오개념이 고착화될 위험이 있고 검증에 시간이 오래 걸린다는 단점이 있다. Solar Teacher는 이 검증 과정을 자동화해 학습 효율을 높이기 위해 시작했다.
주요 기능
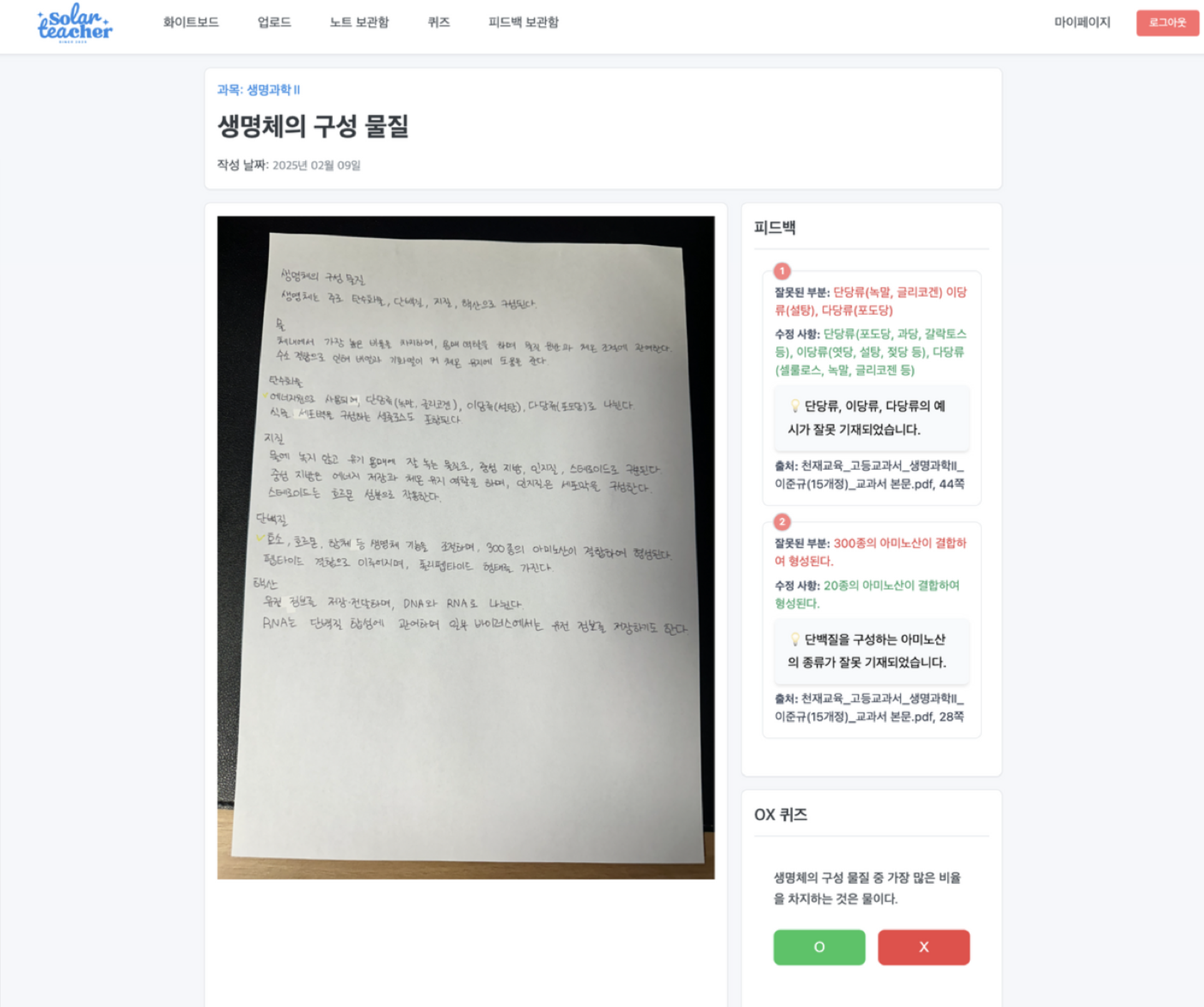
- OCR 기반 노트 디지털화
- 손글씨/인쇄 자료를 Upstage OCR로 텍스트화해 저장
- RAG 기반 AI 피드백
- 사용자 노트와 교과서/연계 교재(RAG DB)를 비교해 오개념을 찾아 설명 제공
- 맞춤형 퀴즈 자동 생성
- O/X 퀴즈 및 4지선다 문제를 자동 생성해 핵심 개념 점검
- 학습 대시보드
- 과목별 학습 통계/정답률/학습 관리 기능 제공
기술 스택
- Language & Framework: Python, FastAPI, LangChain
- LLM & AI: Upstage Solar-Pro (Chat & Embedding), OpenAI GPT-4o (Evaluation Data Gen), Upstage OCR
- Vector DB: Pinecone (Serverless)
- Database: MySQL (User/Note Data)
- DevOps & Tools: Docker, LangSmith, GitHub
- Frontend: HTML/JS/CSS (Basic UI)
문제 해결 및 트러블 슈팅
1) 비정형 노트 데이터를 위한 Semantic Chunking 도입
사용자 노트는 한 페이지에 여러 주제가 섞여 있거나 문맥이 끊기는 경우가 많아 고정 크기 청크로는 검색 품질이 떨어졌다. 이를 해결하기 위해 문장 단위 임베딩을 먼저 생성하고, 문장 간 의미 유사도가 크게 변하는 지점을 기준으로 묶는 Semantic Chunking 전략을 적용했다.
결과적으로 비정형 노트에서도 문맥을 유지한 채 관련 교과서 내용을 더 정확히 검색할 수 있었다.
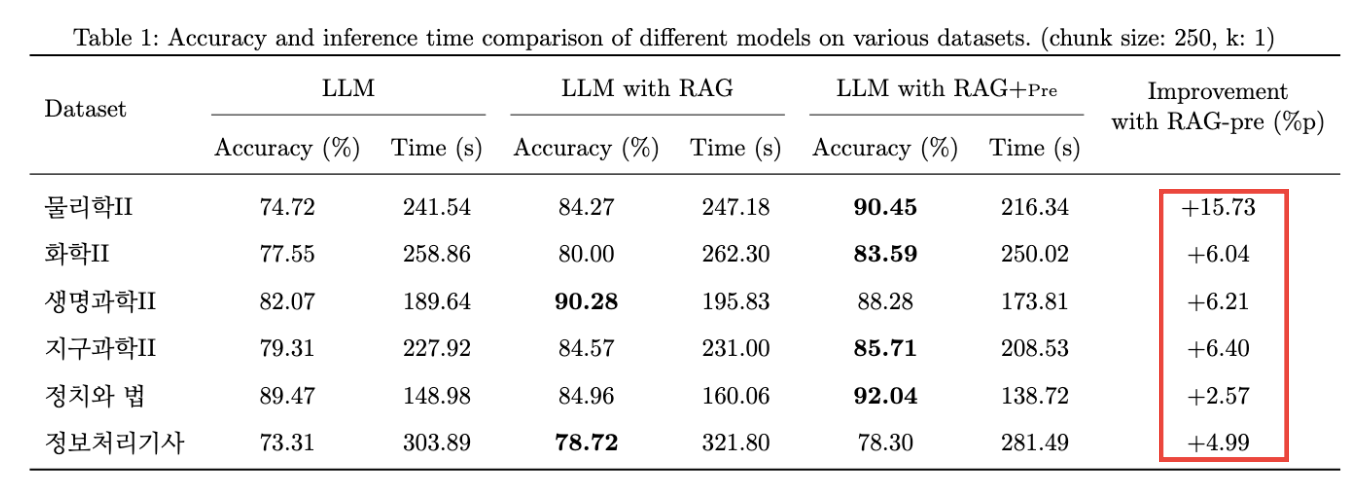
2) 정량적 성능 평가로 RAG 효용성 입증 (+15.73%p)
“RAG가 좋다”를 감으로 말하지 않기 위해, GPT-4o로 6개 과목 기반 **1,000개+ O/X 벤치마크(틀린 문장 찾기)**를 직접 생성해 Golden Dataset을 구축했다. 이후 Chunk Size(250/500/1000)와 Top-K(1~4) 조합을 바꿔가며 실험했고, 병렬 처리를 위해 ThreadPoolExecutor로 API 요청을 5개 스레드로 최적화했다.
- 결과: RAG 적용 시 Base LLM 대비 평균 7~15%p 정확도 향상 (예: 물리학II +15.73%p)
- 최종 파라미터: Chunk Size 250, Top-K 1
3) LLM 출력 안정화 (Structured Output)
퀴즈/평가에서 JSON 포맷이 필요했지만, Upstage Solar 모델은 네이티브 structured output이 강하지 않아 파싱 에러가 발생했다. 이를 해결하기 위해 JsonOutputParser + Pydantic으로 스키마를 명시하고, Upstage Prompt Cookbook을 참고해 JSON 지시 대신 XML 태그 기반 프롬프트로 구조를 강제해 안정성을 높였다.
결과적으로 파싱 에러율을 1% 미만으로 낮춰 배치 처리 안정성을 확보했다.
내가 맡은 역할 (핵심 기여)
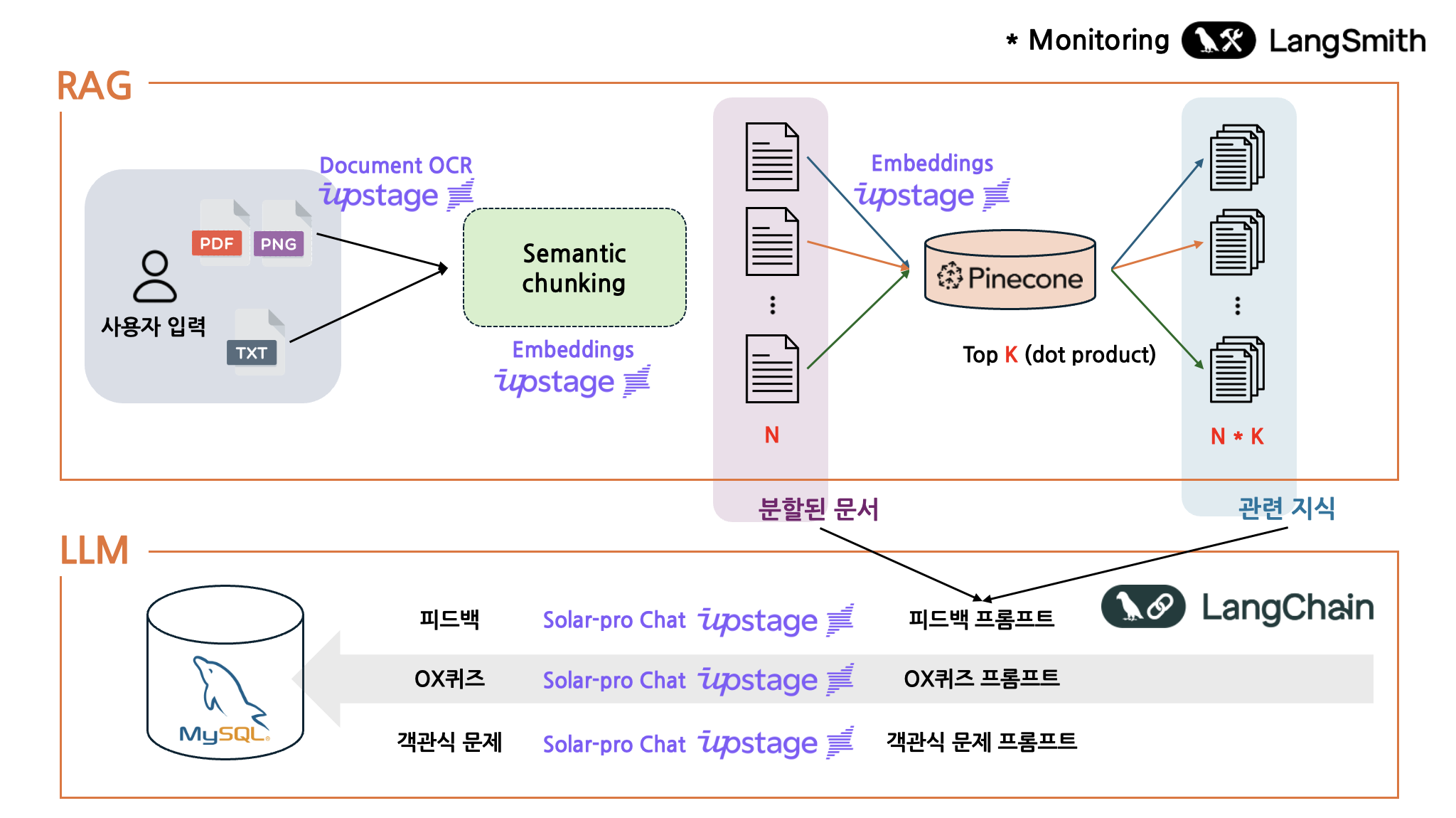
- Pinecone 벡터 DB 구축
- 15개 과목 교과서/수능완성 등 PDF를 수집 → 불필요 페이지 제거/전처리 → 5,080개 청크로 분할 → 임베딩 후 인덱스 구축
- RAG 파이프라인 구현
- LangChain 기반 RAG 설계, 로딩 속도 실험 후 PyMuPDFLoader 채택, 비정형 노트 대응을 위해 SemanticChunker 도입
- 평가 데이터셋 구축
- RAG DB와 분리된 교과서 내용으로 6개 과목 1,000개+ O/X 평가 데이터셋 생성(GPT-4o)
- 실험/파라미터 튜닝
- Chunk size & Top-K 실험으로 LLM 단독 대비 7~15%p 개선 확인, 최종 파라미터 도출
- 피드백 생성 출력 포맷 안정화
- Pydantic 템플릿 + Parser + XML prompting으로 비정형 출력 문제 해결
결과 및 다음 단계
업스테이지 해커톤 최종 발표에서 좋은 평가를 받아, Upstage Edu에서 코스로 제작하고 싶다는 제안을 받아 실제 코스로도 제작하게 되었다.
- 코스 링크: Solar Teacher 코스