추천 시스템 정리 (1)
부스트캠프 AI Tech RecSys Track에서 학습한 강의들을 바탕으로 정리한 글입니다.
Basic
유저는 직접 검색을 하지 않아도, 추천 알고리즘에 따라 유저의 취향에 맞는 아이템을 추천 받는다. (1) 유저의 직접적인 가이드가 없는 상황에서도 아이템을 선별해 주는 것과, (2) 다양한 아이템을 추천해 주는 것(long tail recommendation)이 추천 시스템의 핵심이다.
데이터
- 유저 정보
- 유저 프로파일링, 식별자, 유저 행동 정보 등
- 아이템 정보
- 아이템 고유 정보
- 유저 - 아이템 상호작용 정보
- explicit feedback: 별점과 같은 직접적인 선호 정보
- implicit feedback: 클릭 로그, 구매 이력 등 간접적인 선호 정보
문제 정의
- Ranking
- 유저에게 적합한 아이템 K개를 추천하는 문제
- 유저의 아이템들 간 선호 순서를 학습
- Precision@K, Recall@K, MAP@K, nDCG@K
- Prediction
- 유저가 아이템에 가질 선호도를 정확하게 예측하는 문제
- 평점 예측, 구매할 확률 예측 등.
- MAE, RMSE, AUC 등으로 평가
Evaluation Metric
추천 모델을 가장 쉽게 평가하는 방법은 offline 평가이다. 데이터셋을 Train, Valid, Test로 나눠 수치적으로 모델의 성능을 평가한다. offline 평가의 성능이 좋다고 항상 online 성능이 보장되는 것은 아니지만, 모델을 배포하기 전에 평가가 가능하다는 이점이 있어 사전 검증용으로 쓰인다.
Precision@K
추천한 K개의 아이템 가운데 실제 유저가 관심있는 아이템의 비율
Recall@K
유저가 관심있는 전체 아이템 가운데 추천한 아이템의 비율
AP@K
Precision@1부터, Precision@K까지의 평균값
관련 아이템을 더 높은 순위에 추천할수록 점수가 높아진다.
MAP@K
모든 유저에 대한 AP값의 평균
nDCG
-
Cumulative Gain (CG): 상위 K개 아이템에 대하여 관련도를 합한 것
-
Discounted Cumulative Gain (DCG): 순서에 따라 가중치 부여
-
Ideal DCG (IDCG): Ideal한 DCG
-
Normalized DCG (NDCG): 추천 결과에 따른 DCG를 IDCG로 나눈 값
인기도 기반 추천
Most Popular Recommendation
Hacker News Formula
- 시간이 지남에 따라(age가 증가함에 따라), score 감소
Reddit Formula
- 인기도 + 포스팅 시간 가중치
Stream Rating Formula
- 리뷰 개수에 따른 가중치를 부여
Collaborating filtering
많은 유저들로부터 얻은 기호 정보를 이용해 유저의 관심사를 예측하는 방법
목표
유저 u가 아이템 i에 부여할 평점을 예측하는 것
방법
- 유저-아이템 행렬 생성
- 유저, 아이템 간 유사도 계산
- 나머지 비어있는 부분 채우기
Neighborhood-based CF
Memory-based CF라고도 한다.
특징
- 구현이 간단
- 새로운 아이템, 유저에 대한 낮은 확장성
- sparsity ratio가 99.5%를 넘으면 성능이 떨어짐 -> 넘을 경우 Matrix Factorization 추천
K-Nearest Neighbors CF (KNN CF)
- NBCF의 모든 관계를 학습해야 하는 단점을 극복
- 유저 u와 가장 유사한 K명의 유저를 이용해 평점 예측(K 값은 보통 25 ~ 50 사이값으로 튜닝)
유사도 측정법
- Mean Squared Difference Similarity
- 유클리드 거리에 반비례
- Cosine Similarity
- 두 벡터가 가르키는 방향의 유사도(크기는 무시됨)
- Pearson Similarity (Pearson Correlation)
- 각 벡터를 표본평균으로 정규화한 뒤에 코사인 유사도를 구한 값(유저마다 평점을 주는 분포가 다르기 때문)
- 직관적인 해석: (X와 Y가 함께 변하는 정도) / (X와 Y가 따로 변하는 정도)
- Jaccard Similarity
- 주어진 두 집합 A, B에 대해 계산
- 벡터가 아니기 때문에, 서로 길이가 달라도 됨.
- 두 집합이 얼마나 같은 아이템을 공유하고 있는지 나타냄.
- 두 집합이 가진 아이템이 모두 같으면 1, 하나도 없으면 0
유사도 측정 방법은 오프라인 테스트를 통한 성능을 근거로 결정할 수 있다.
Model Based Collaborative Filtering
항목 간 유사성을 단순 비교하는 것에서 벗어나 데이터에 내재한 패턴을 이용해 추천하는 방법
NBCF의 한계
- sparsity
- scalability
해결 방법
- Parametric Machine Learning을 사용, 데이터 정보가 파라미터의 형태로 모델에 압축
- 유저-아이템 데이터는 학습에만 사용되고 학습된 모델은 압축된 형태로 저장됨
- limited coverage 극복
Latent Factor Model
유저와 아이템을 저차원의 행렬로 분해, 유저와 가까운 위치의 아이템을 추천
Singular Value Decomposition (SVD)
- Item-User Rating Matrix를 분해
- 한계: 결측된 entry를 모두 채우는 imputation을 통해 Dense Matrix를 만들어 SVM를 수행 즉, 빈 칸을 0 또는 유저, 아이템 평균 평점으로 채움 → 기존 데이터가 왜곡되기 쉬움.
- 전체 factor를 쓰는 Full SVD와 일부 factor를 쓰는 Truncated SVD가 있음.
Matrix Factorization
SVD와 유사하지만, 관측된 데이터만 활용하여 Rating Matrix를 잠재 요인의 행렬 곱으로 근사하자.
objective function
실제 관측값과, latent vector의 곱이 가까워지도록 학습하는 term + vector에 대한 L2 정규화 term
학습
-
SGD
Gradient의 반대방향으로 , 를 업데이트
-
ALS
-
행렬(P)과 아이템 행렬(Q)을 번갈아 고정하고, 고정한 상태에서 다른 하나를 Least Squares 방식으로 해결
-
새로운 objective function
-
추가 개선
Matrix Factorization Techniques for Recommender Systems
-
Adding Biases: 개별 유저와 아이템에 대한 편향 b를 학습함
-
Adding Confidence Level: 데이터의 신뢰도를 의미하는 c 파라미터를 추가
-
Adding Temporal Dynamics: Adding Temporal Dynamics
Neural Matrix Factorization
기존 Matrix Factorization에 MLP를 추가하여, user-item의 복잡한 관계를 학습
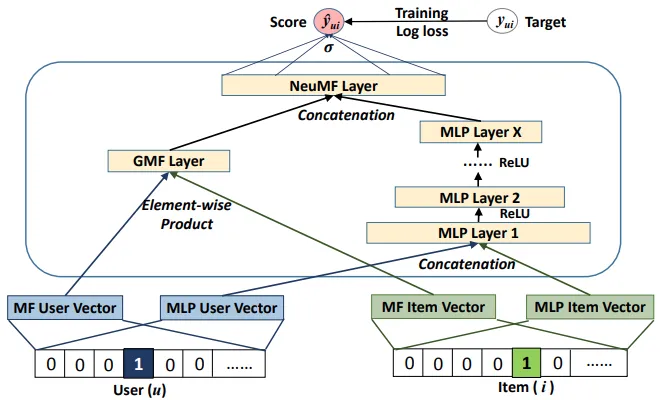
출처: Neural Collaborative Filtering
Bayesian Personalized Ranking (BPR)
사용자에게 순서가 있는 아이템 리스트를 제공하는 문제
유저의 아이템에 대한 선호 순위를 Matrix Factorization 학습에 반영
BPR: Bayesian Personalized Ranking from Implicit Feedback
가정
- 관측된 item을 관측되지 않은 item보다 선호
- 관측된 것들 사이에 선호도 추론 불가
- 관측되지 않은 것들 사이에 선호도 추론 불가
특징
- 관측되지 않은 아이템도 학습함
- 관측되지 않은 아이템 간에도 ranking이 가능
최대 사후 확률 추정(Maximum A Posterior, MAP)
주어진 유저 선호 정보를 최대한 잘 나타내는 파라미터를 추정
-
모든 유저 선호 정보() 에 대한 likelihood:
-
objective function
| 항목 | Memory-based | Model-based |
|---|---|---|
| Training and Inference Complexity | - Training 필요 없음 Inference를 위해서 많은 양의 Offline 계산(similar-item tables을 만드는 작업)이 요구됨 | - 모델 학습을 위해 값비싼 offline training이 요구됨 한 번 학습된 후에는 비교적 빠르게 inference 가능함 |
| Interpretability | - Interaction 데이터 기반의 similarity를 계산하여 활용하기 때문에 추천의 이유에 대해 직관적인 설명을 제공함 | - Parametric 모델의 특성 상 black-box인 측면이 있음 |
| Accuracy | - 직접적으로 accuracy 메트릭을 최적화하지 않으므로 불리함 (휴리스틱 방법의 한계) | - MSE 등의 objective function을 직접적으로 최적화하므로 유리함 |
Item2Vec
Embedding: 주어진 데이터를 낮은 차원의 벡터로 표현하는 방법이다. 벡터 공간 상에서 의미 기반의 연산이 가능해진다. 추천 시스템에서는 유저와 아이템을 벡터로 나타내고, 이 벡터들 간의 유사도를 기반으로 추천을 수행한다.
Sparse Representation
- one-hot encoding, multi-hot encoding처럼 전체 feature 공간에 걸쳐 희소하게 표현됨
- 차원이 높고 연산이 비효율적
Dense Representation
- 비교적 작은 차원에 정보를 압축하여 표현
- 연산 효율성과 의미 표현력이 높음
- 추천 시스템의 핵심 표현 방식
Word Embedding
단어를 dense vector로 표현하는 방법. 자연어 처리 분야에서 발전된 기법들이 추천 시스템에서도 유사하게 적용된다.
Word2Vec
단어 간의 관계를 벡터 공간 상에서 학습해 표현하는 뉴럴 네트워크 기반 기법이다.
특징
- 대량의 코퍼스에서 학습
- 의미를 내포한 벡터 표현
- 연산 효율이 높고 빠르게 학습 가능
- 유사한 단어는 벡터 공간 상에서 가까운 위치
학습 방법
- CBOW (Continuous Bag of Words)
- 주변 단어들을 이용해 중심 단어를 예측
- 전체 문맥의 평균을 통해 예측
- Skip-Gram
- 중심 단어로 주변 단어들을 예측
- 일반적으로 CBOW보다 성능이 더 좋음
- Skip-Gram with Negative Sampling (SGNS)
- 실제 단어쌍은 label 1, 무작위 단어쌍은 label 0으로 binary classification
- 하나의 positive sample마다 여러 negative sample 생성
- 효율적으로 대규모 데이터셋 학습 가능
Item2Vec
Word2Vec의 아이템 버전. 단어 대신 아이템을 사용해 유사한 방식으로 벡터화한다.
- 유저의 item sequence를 문장처럼 간주
- 유저의 행동 로그를 기반으로 아이템 간의 관계를 학습
- Skip-Gram 기반으로 학습하는 경우가 일반적
- 유사 아이템 검색, 추천, 군집화 등에 활용 가능
ANN (Approximate Nearest Neighbor)
벡터 공간 상에서 내가 원하는 query vector와 가장 유사한 벡터를 빠르게 찾는 알고리즘이다.
Brute Force KNN
- 모든 벡터와 유사도를 직접 계산하여 가장 가까운 벡터를 찾는 방식
- 연산 정확도는 높지만, 연산량이 벡터 수에 따라 선형적으로 증가해 속도가 매우 느림
ANN
정확도를 조금 포기하고 빠른 속도로 근접 이웃을 찾자.
ANNOY
- Spotify에서 개발한 tree-based ANN 알고리즘
- 벡터를 여러 subset으로 나눠 tree 구조로 구성한 후 탐색
작동 방식
- 임의의 두 벡터를 선택
- 두 점 사이의 하이퍼플레인으로 공간 분할
- 이 과정을 반복하며 binary tree 생성
특징
- 여러 개의 tree를 구성하여 병렬 탐색을 통해 정확도를 보완
- Priority Queue를 이용해 주변 subset도 탐색
- 기존 tree에 새로운 벡터 추가 불가
- 벡터 차원이 낮고 아이템 수가 적은 경우 적합
주요 파라미터
n_trees: 생성할 tree의 개수search_k: 탐색 시 고려할 node 수
HNSW (Hierarchical Navigable Small World Graph)
벡터들을 노드로 하고, 유사한 노드끼리 edge로 연결하여 그래프로 구성
계층적 구조를 통해 빠르고 정교하게 탐색 가능
작동 방식
- 최상위 레벨에서 임의 노드로 시작
- 현재 레벨에서 가장 가까운 노드로 점프
- 하위 레벨로 내려가며 탐색 반복
- 마지막 레벨에서 근접 이웃 탐색 후 종료
IVF (Inverted File Index)
- 전체 벡터를 clustering한 후, 각 cluster를 inverted list로 저장
- query가 속한 cluster에서만 탐색 → 연산량 감소
- cluster 수를 조정하여 정확도 vs 속도 트레이드오프 조절 가능
Product Quantization (PQ)
고차원 벡터를 를 n개의 centroid로 압축하여 빠르게 탐색
작동 방식
- 벡터를 여러 sub-vector로 분할
- 각 sub-vector 그룹마다 k-means를 통해 centroid 생성
- 모든 벡터를 해당 centroid의 인덱스로 표현
- 벡터 간 유사도 계산이 거의 필요 없음 (O(1))